Getting a Job in the AI Industry: Part 1
You don't have to be a data scientist or a technical expert to get a job in the AI industry. Here I explain some of the key concepts you would do well to educate yourself on.


The AI industry is HOT right now. You cannot spend any time online and not hear about it in some shape or form. Therefore it’s no surprise that many people are looking to take a role within the sector given it’s exciting trajectory for personal development and a rewarding career.
According to the PwC 2024 AI Jobs Barometer, “AI jobs are growing 3.5x faster than for all jobs. For every AI job posting in 2012, there are now seven job postings”, and “jobs that require AI skills carry up to a 25% wage premium in some markets”.
Despite the core of AI being data science, there are many other aspects and roles within AI companies for which you might have the skills and experience required to land a job. In this short series, I’ll explore some fundamental areas to help you with your job search.
I landed my current role at Dataiku through my extensive experience in customer success, and my exposure to AI was fairly limited until I joined. Still, having worked in the digital marketing industry for 20+ years, I have a solid data and analytics foundation. If you aspire to get a role at an AI company but don’t have a data science background, there are still plenty of opportunities. In Part 1, we’ll take a look at some of the main technical concepts you should try to understand.
What is AI?
Let’s start right at the top. What is AI?
Having a certain level of understanding as to what AI is should be the foundation of any further learning. AI is a very complicated field, but there are some top level concepts that can easily be understood. If you’re in the market for a job in the AI sector, you’ll no doubt be flooded with news around Generative AI and the likes of ChatGPT, but this is just one of the latest developments in a broader field.
Artificial Intelligence (AI) - The term AI is now over half a century old. It’s a broad phrase for the simulation of human intelligence by computer systems. It includes Machine Learning, NLP, Robotics, Neural Networks, Genetic Algorithms, and more.
Machine Learning (ML) - Machine learning is a subset of AI that uses historical data to produce outputs for specific tasks. Historically, when people mentioned ‘AI’, they are most likely referring to ML. That said, generative AI is quickly becoming what we think of. ML use cases typically involve forecasting a number or spotting patterns in data sets.
Deep Learning - Deep learning, a subset of ML, mimics our understanding of the human brain and neural networks. It can automatically adapt with minimal human interference. "Deep" refers to the use of multiple layers in the network and requires enormous computational power. A famous example of Deep Learning is the AlphaGo computer programme that beat the world Go champion, Fan Hui.
Coding/Programming
Whilst programming languages like Python and R are ubiquitous in data science, you do not need to learn them. In fact, with how AI software is going, the need for a business user to learn these languages is reducing to near zero. I wouldn't even think about starting if you don’t already have some programming skills. So many other areas in AI will be far more worthwhile to invest your energy in.
As with many subjects, understanding topline themes and topics can be helpful, though:
Integrated Development Environment (IDE) - Coders have specific data science programs for their development work. The main applications being VS Code,
Notebooks - Somewhat similar to an IDE, a notebook is a specific application for data science. A key aspect to Notebooks is that they contain cells which can be run independently. The preeminent notebook provider is Jupyter, but you can also find plenty of others.
Stackoverflow - A website that allows users to post questions relating to coding problems, and fellow users can give tips, guidance, and, very often, fully working code. Interestingly, this stalwart of the programming world is now facing a large downturn in traffic due to the emergence of generative AI and its ability to suggest code.
Python - A popular and versatile general-purpose language known for its simplicity and wide use in data science, web development, and automation.
R - A more specific language used for statistical programming, data analysis, visualization, and machine learning.
SQL - A specialised language for managing and querying relational databases.
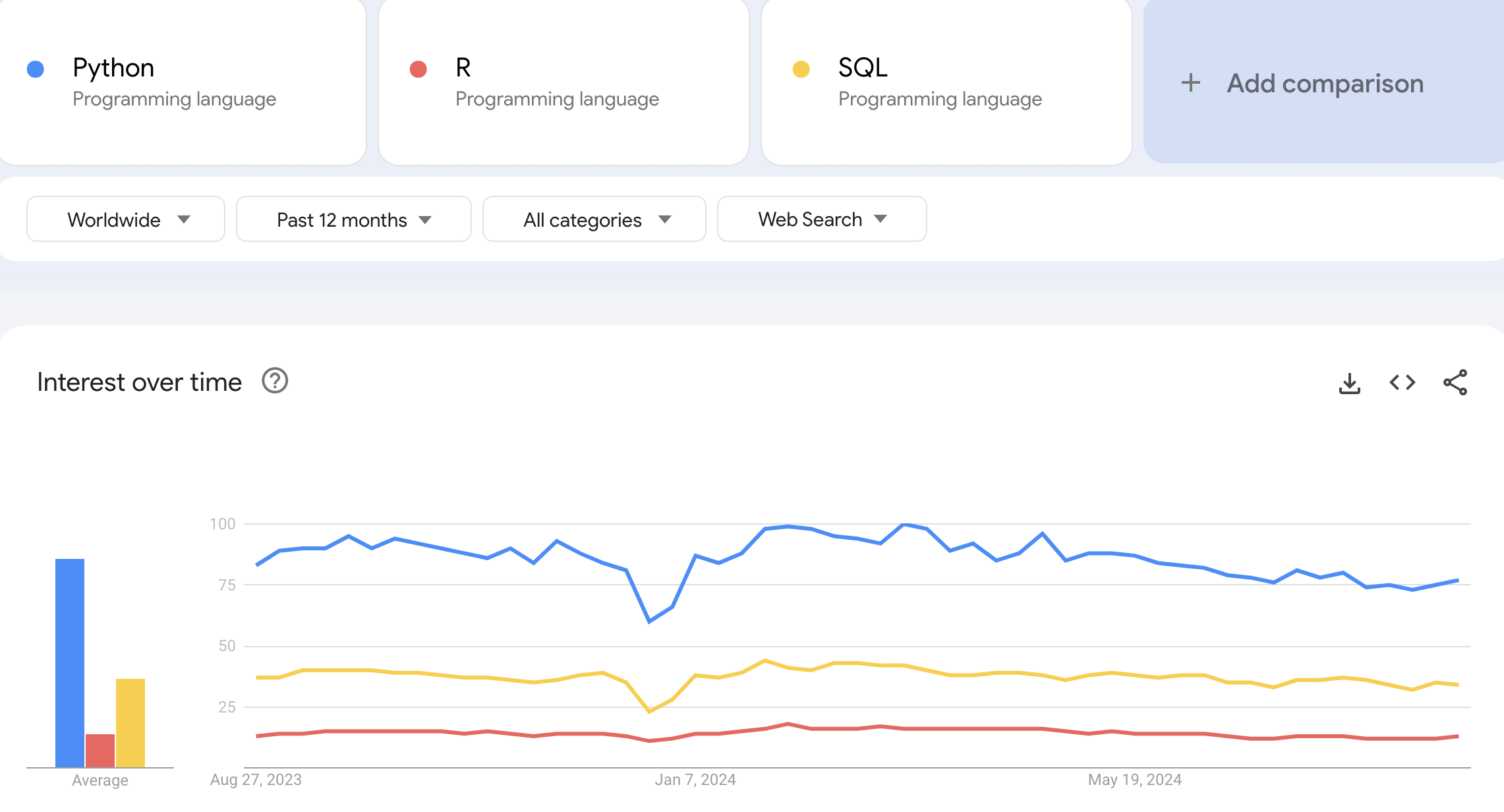
When looking on Google Trends to identify which language receives the most interest, Python is by far the most popular.
Governance
This is a hugely important one and probably the topic I hear least about when people talk about AI. Ensure you understand that putting an AI project live can have significant implications. With the EU AI Act coming into force on August 1, 2024, there are very real consequences for getting AI wrong.
I could write several articles dedicated to just governance, but for now, let’s take a look at some key aspects:
Data Access
Right at the very beginning of any project, you should be clear about what data is going to be used, who’s using it, where it will be used, and for what. Almost every enterprise sized company will have a clear framework relating to its data. Get comfortable with the concepts of data lakes (warehouses), data stewards, access requests etc. Many companies might also adopt User Groups in their systems that allow grouping of permissions based on a job role or department, for example.
Bias/Ethics
When building AI models, it’s very important that there is no bias in the data. Not only will this make your model more accurate, but it will also keep you away from potential ethical issues. For instance, if you’re building a model to provide a credit limit for credit card applications, you don’t want to have any gender bias in your data.
Approval Process
Building AI models isn’t just for fun; after some work and effort, you’ll likely want to put the model to use in the business. However, there must be a robust approval process before models go live in Production. Individual processes will vary per organisation, but the core theory will remain the same, in that designated individuals should be responsible for approving or denying the model.
Data Connections
You should also understand where data is stored, both where it is coming from and where it is going. Depending on the use case, data might be coming from on-premise databases (Microsoft SQL, Oracle), 3rd party solutions (CRM), cloud storage (GCP, AWS, Azure) and increasingly more common, cloud databases such as Databricks or Snowflake. Coupled with the emergence of LLMs, we’re now seeing Vector databases grow in popularity.
Data Preparation
Depending on what role you might end up in, you might not work with a lot of raw data, but be aware that data preparation tasks are the biggest part of any AI project. As with any data project, you cannot escape the fact that the data you are working with must be accurate. Since you’re reading this article, I imagine you’re familiar with data cleansing, categorisation, normalisation, etc. Likely, you’ve already done a ton of this in your career in Excel and working with an AI project will be no different. Some research by Crowdflower suggests that a Data Scientist will spend 60% of their time on data preparation and another 20% collecting datasets. i.e. it’s unavoidable.
Operations
From all of the above, we can see that developing AI projects is quite a complicated process. There are various steps leading up to training a model, and many more steps needed to deploy it. A specific area has emerged that we call MLOps (Machine Learning Operations); that covers the entire end-to-end process of a project. Concepts here would be items such as setting up different environments (development, testing/staging, production). Version control. Continuous Integration/Continuous Deployment (CI/CD). Model deployment/monitoring. Many of these tasks are covered by the role of an MLOps Engineer.
Use Cases
None of the above is at all relevant unless you have a project use case. Typically, a use case relates to a specific business problem that someone has identified. For a use case to be successful, you should ensure you have a clear and defined goal, a measure of success, and a timeline for when it needs to be delivered. Personally, I find this one of the most interesting areas of my job when I look at the vast range of different use cases our clients build projects for. Don’t come with pre-determined ideas of the solution, rather, work with colleagues to weigh up all the options and understand which is the most suitable. At the minute, generative AI and LLMs are very popular but they can also be expensive and not always 100% accurate. For some use cases, more ‘traditional’ machine learning methods, such as Natural Language Processing (NLP), might be better. Don’t be the proverbial magpie, and go for the latest shiny thing when simpler solutions are available.
Whatever role or company you might end up interviewing with, I strongly suggest you research their publicised use cases; typically, these can be found on a website under the heading of ‘Success Stories’ or ‘Customer Stories’ or similar. This will give you a good feel for the type of problems the company solves and a sense of what they do.
Already a lot to take in, given that this is just topline stuff, and in Part 2, we’ll go even broader and look at the different types of companies you might find yourself applying to for an AI job.



